Time Series CV Sklearn
- 4 minsMake a model. Split your data, train, test.
Question yourself whether the test set is well represented.
Apply the KFold cross validator from sklearn to see how the model works on ‘folds’ of data.
Realise your data has a temporal (time-based) component and randomly picking test windows makes little sense.
Change your train, test strategy to test on the most recent data.
Explore time-series cross validation methods and try out TimeSeriesSplit from sklearn.
Dig into how it works, realise it’s less of a time-series cross validator than its name suggests…
How does TimeSeriesSplit work?
Provides train/test indices to split time-ordered data, where other cross-validation methods are inappropriate, as they would lead to training on future data and evaluating on past data. To ensure comparable metrics across folds, samples must be equally spaced. Once this condition is met, each test set covers the same time duration, while the train set size accumulates data from previous splits.
However, there is one, big pre-requisite:
- Your data must be ‘ordered’ before passing it to
TimeSeriesSplitas it has no concept of time.
After that, the arguments are as follows:
n_splits(int) [defaults to 5]: the number of splits (folds)max_train_size(int) [defaults to None]: the maximum size of a single folds train sizetest_size(int) [if None, defaults ton_samples // (n_splits + 1)]: used to limit the size of the test setgap(int) [defaults to 0]: number of samples to excluse at the end of each folds train set before the folds test set
Below shows how this theoretically works depending on if max_train_size has been set, or not.
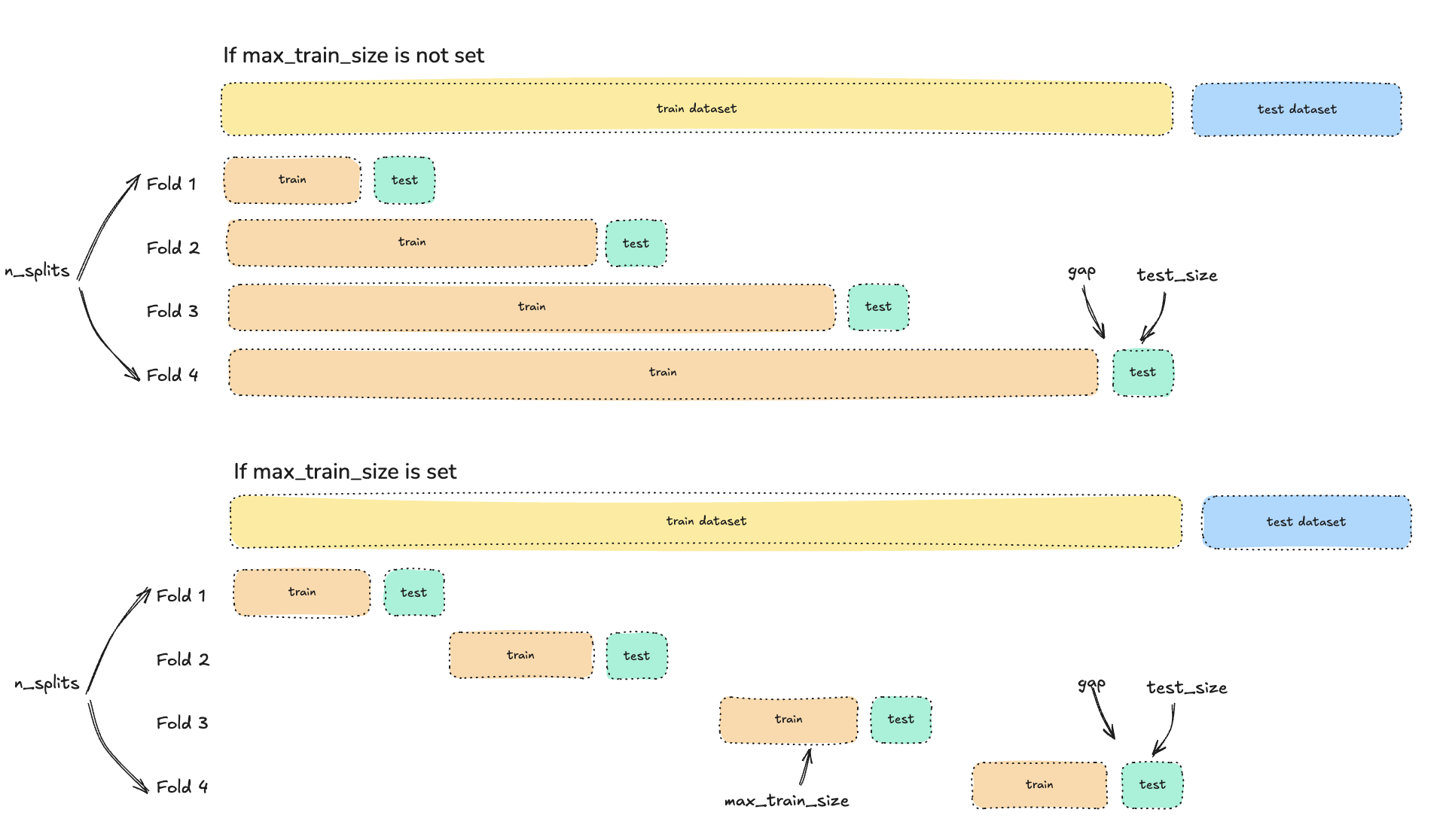
Problem 1: Fold test windows logic is weird
However, this is slightly misleading due to how TimeSeriesSplit creates where the test windows should start. See the code here, and pasted below too.
test_starts = range(n_samples - n_splits * test_size, n_samples, test_size)
Working through this, it creates a range(start, stop, step) where start is n_samples - n_splits * test_size, stop is n_samples (i.e. the end of the dataset) and the step is test_size.
This is slightly unusual as it creates a situation where the start is itself governed by the test_size. Examples:
Example 1 (n_samples = 10,000, n_splits = 10, test_size = 100)
start= 10,000 - (10 * 100) = 9,000stop= 10,000step= 100
The test start array created would be [9000, 9100, 9200, 9300, 9400, 9500, 9600, 9700, 9800, 9900]
So essentially we are only applying a cross validation to the final 10% of our data, not at regular intervals.
Example 2 (n_samples = 10,000, n_splits = 10, test_size = 500)
start= 10,000 - (10 * 500) = 5,000stop= 10,000step= 500
The test start array created would be [5000, 5500, 6000, 6500, 7000, 7500, 8000, 8500, 9000, 9500]
Just by increasing our test_size we are evaluating further back into our dataset.
Weird.
Problem 2: There is no time series element to this method
For a method called TimeSeriesSplit you would assume the data would need to have both a time-series component, and this would be used in the split. You’re wrong.
The ‘one, big pre-requisite’ of data required to be ‘ordered’ is just that, simple ordering. The method works the same way as if you ordered your data based on a count value and then wanted to cross validate across increasing count values. There is nothing time series about this approach.
A major flaw in the inner workings of TimeSeriesSplit is that there is no way to fix your fold test windows for moments in time. Want to understand how your model performs for the turn of each Quarter? Tough luck. And even if you did manage to find the correct parameter values, if your dataset grew in the future, these windows would have been shifted by the internal logic anyway.
Instead of TimeSeriesSplit, the method should be called OrderedSplit, because fundamentally, that’s all it does.
What next? Build a proper time-series cross validator that works with sklearn.
The aim is to build a proper time-series cross validator that can do the following:
- Provides a parameter for the user to specify ‘time/date’ for fold generation
- Allows the user to all prior data in the fold train window, or specify a date/time rolling window
Work in next blog.

Michael Hodge
Data Scientist